The Agentic AI Product Playbook: Building 0-to-1 Products from First Principles
A comprehensive guide to building AI systems that think, not just features that respond.
Executive Summary
This playbook presents my first-principles approach to building agentic AI systems that deliver transformative business value. I've found that most AI projects fail by treating symptoms rather than understanding the user's underlying cognitive processes. My core thesis is that to succeed, product teams must move beyond building simple "AI features" and instead architect AI systems that think.
Through a detailed case study of automating a corporate travel agency, I demonstrate a rigorous, four-part methodology for building these systems from the ground up:
| Phase | Title | Focus | Key Outcome |
|---|---|---|---|
| Part 1 | The Discovery Engine | Deconstructing the problem space through deep user observation and cognitive science. | A validated understanding of the user's mental model and "decision atoms." |
| Part 2 | The Cognitive Blueprint | Translating human thought processes into a multi-agent architecture. | A clear design for a mesh of specialized AI agents that collaborate to solve the problem. |
| Part 3 | The Implementation Playbook | Executing the technical build with a focus on production-readiness. | A robust, observable, and debuggable system with real code examples and failure-handling. |
| Part 4 | The Business Case | Proving the economic viability and go-to-market strategy. | A clear ROI analysis, pricing model, and GTM plan grounded in real-world data. |
Key Insights & Business Impact
The case study yielded significant, quantifiable results, proving the power of this methodology:
- Massive Efficiency Gains: The agentic system reduced the time to create a travel proposal from 4 hours to just 5 minutes of human review—a 98% reduction.
- 3x Capacity Increase: Each travel professional could manage 150 trips per month, up from 50, tripling the company's revenue capacity without increasing headcount.
- Compelling ROI: The system delivered $191 in net savings per proposal, with a payback period of just 1.3 years on the initial development cost.
- Dominant Cost Driver: My analysis revealed that human review time ($4.17/task), not LLM costs ($0.58/task), is the primary operational expense. This highlights the critical importance of system accuracy and reliability.
The Bottom Line for Leaders
Agentic AI is not about replacing humans but about augmenting their cognitive capacity. Building successful AI products requires a fundamental shift in mindset from feature-level thinking to systems-level thinking. By investing in a deep, upfront discovery process to understand user cognition, you can design and build AI systems that deliver a step-change in productivity and create a powerful competitive advantage.
This playbook provides a replicable blueprint for any organization looking to move beyond the hype and build truly impactful, production-ready agentic AI solutions.
 The 4-part methodology: From discovery to production to business viability
The 4-part methodology: From discovery to production to business viability
Introduction: The Illusion of the Problem
Most product teams fail not because they build the wrong solution, but because they solve the wrong problem. They see a user struggling with a search box and build a better search box. They see a user spending hours on a task and try to make the task faster. They are treating symptoms, not diagnosing the underlying disease.
This playbook is about a different approach: first-principles thinking applied to user cognition. It's about deconstructing not just the user's workflow, but the user's thought process. I go beyond what users do and into how they think.
Agentic AI is not a technology to be applied; it is a new paradigm for modeling and automating human cognition. The goal is not to build a faster tool, but to build a synthetic colleague that can share the cognitive load.
When I consult with startups and scaleups building AI products, I see the same pattern repeatedly: teams rush to implement the latest LLM capabilities without understanding the fundamental problem they're solving. They build "AI features" instead of "AI systems." They add a chatbot to their product and call it "agentic." This is not agentic AI.
True agentic AI requires a deep understanding of human cognition, a rigorous analytical process, and a willingness to challenge your assumptions about what the user actually needs. It requires you to think like a cognitive scientist, not just a product manager.
This case study demonstrates analytical work through a deep dive into a real-world implementation, showing how I combine deep user empathy, first-principles thinking, technical depth, and a relentless focus on business impact. It draws on my experience building AI-powered travel products at Qtravel.ai and consulting engagements with corporate travel agencies.
Note: Names, company identifiers, and some details have been changed for confidentiality. Certain metrics represent composite data from multiple engagements.
I'll explore this methodology through a comprehensive case study of building an AI-powered assistant system for corporate travel professionals. Throughout this article, I use clear terminology to avoid confusion:
- "Travel professionals" or "human travel professionals" refers to the people who work at the corporate travel agency
- "AI agents" or "software agents" refers to the autonomous AI components I built to assist them
- "Agentic system" refers to the complete AI-powered assistant platform
This case study follows a rigorous, step-by-step process:
- Part 1: The Discovery Engine - A 4-week sprint to deconstruct the problem space using behavioral analytics and cognitive science.
- Part 2: The Cognitive Blueprint - Translating human thought processes into an agentic architecture using Jobs-to-be-Done frameworks.
- Part 3: The Implementation Playbook - Tactical decisions on building, debugging, and deploying with real code examples and cost analysis.
- Part 4: The Business Case - A deep dive into unit economics, pricing strategy, and go-to-market approaches with model pricing from early 2024.
This is not a guide to building features. It is a guide to building systems that think.
PART 1: THE DISCOVERY ENGINE
The B2B Corporate Travel Agency Challenge
The Business Context: During my time building AI products in the travel industry, I worked with a 100-person corporate travel agency that was facing an existential scalability crisis. Their business model was built on providing white-glove service to mid-market companies—the kind of personalized attention that self-serve booking tools couldn't match. But this high-touch model was entirely dependent on the heroic efforts of their 60 human travel professionals, and the company was hitting a wall.
The Head of Operations told me in our first meeting: "Our travel professionals are burning out. They spend 80% of their time fighting with our booking systems and 20% actually talking to clients. We can't scale the business this way. We've tried hiring more people, but the training takes 6 months and half of them quit within a year. We need a different solution."
The CEO added: "Our brand is built on providing a premium, personalized service. I don't want to replace our travel professionals with a self-serve portal like Expedia. I want to give them superpowers so they can handle 3x the clients with less stress and maintain that personal touch."
This was the perfect setup for an agentic AI solution, but I needed to understand the problem deeply before proposing anything.
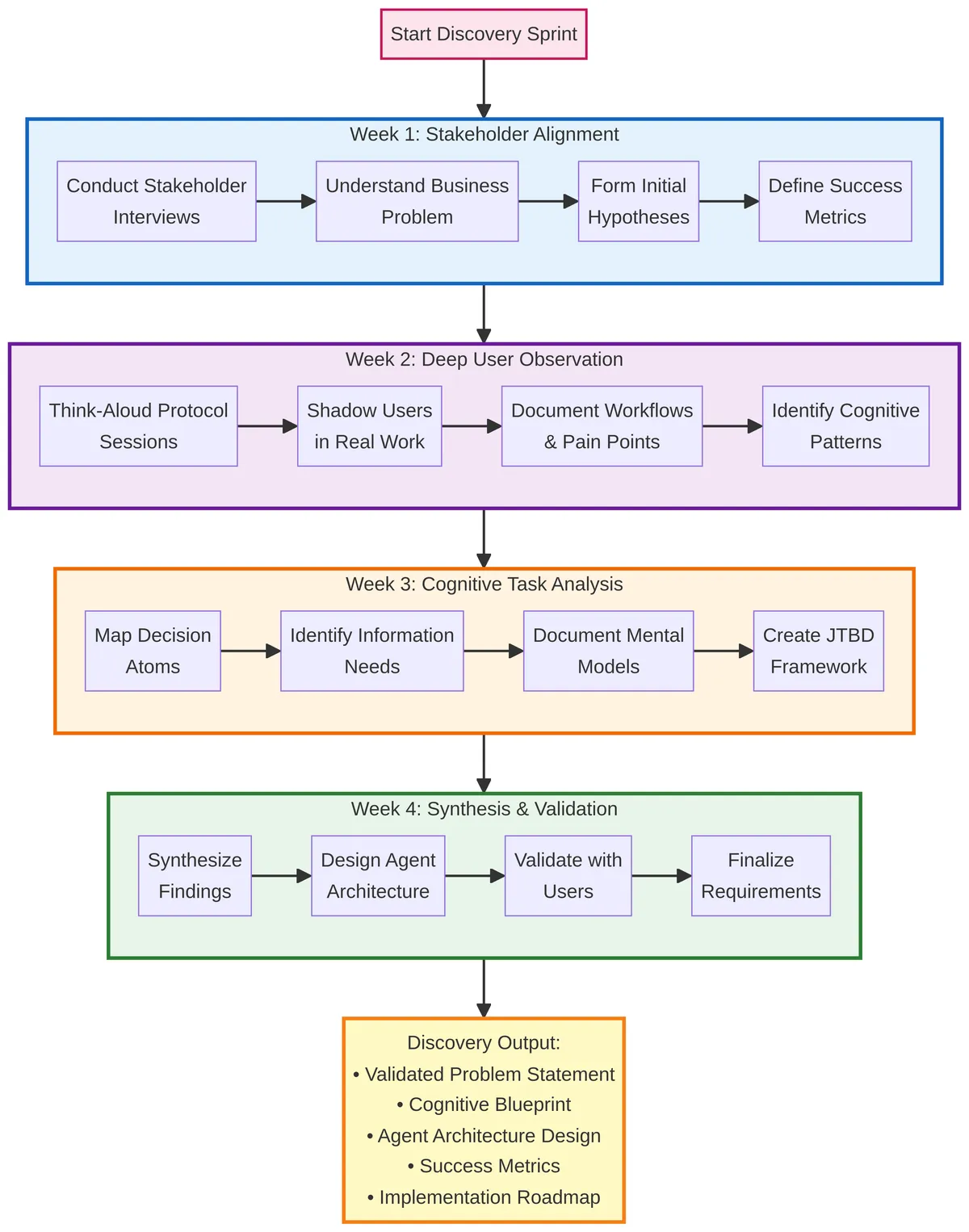 The 4-week discovery sprint: From stakeholder alignment to validated design
The 4-week discovery sprint: From stakeholder alignment to validated design
Chapter 1: The 4-Week Discovery Sprint
Week 1: Stakeholder Alignment & Hypothesis Definition
The first week was about alignment. I conducted four stakeholder interviews: the CEO, the Head of Operations, the Head of Sales, and two of their top-performing travel professionals. My goal was to understand the business problem from multiple perspectives and form initial hypotheses that I could test.
From the CEO, I learned that the company's average revenue per agent was $500K per year, and their target was to get that to $1.5M without sacrificing service quality. From the Head of Sales, I learned that their win rate against competitors was 70% when they could respond to an RFP within 24 hours, but dropped to 30% if it took longer than 48 hours. Speed mattered.
From the travel professionals, I learned that the actual work of creating a travel proposal felt like "playing a giant game of Tetris with a dozen different systems that don't talk to each other." One agent, Sarah, told me: "I love the client interaction part of my job. I love understanding what they need and finding creative solutions. But I spend maybe 30 minutes a day actually doing that. The rest is just... data entry and system-hopping. It's soul-crushing."
Based on these interviews, I formulated a primary hypothesis: "We believe travel professionals are spending the majority of their time on low-value, repetitive tasks (searching, comparing, formatting), which limits their ability to provide high-value, personalized service and creates a bottleneck for business growth."
I agreed with the stakeholders on two primary success metrics:
- Reduce average time-to-proposal from 4 hours to 30 minutes.
- Increase number of trips managed per agent per month from 50 to 150, without increasing headcount.
These metrics were ambitious but grounded in the business reality. If I could hit them, the company could triple its revenue without tripling its workforce.
Week 2: Deep User Observation
The second week was about observation. I embedded myself with the travel professionals, watching them work and asking them to narrate their thought process out loud. This is called the "think-aloud protocol" in cognitive science research, and it's one of the most powerful tools for understanding how people actually think, not just what they do.
I conducted 15 observation sessions with 5 different agents over the course of the week. Here's a complete transcript from one of those sessions with Sarah, a senior agent with 8 years of experience:
Me: "Thanks for letting me shadow you, Sarah. Could you walk me through what you're working on right now?"
Sarah: "Sure. I just got an email from Acme Corp. Their exec team needs to go to London for a conference next month. The email is pretty vague, just says 'need a productive week in London for 4 people, dates flexible within the first two weeks of March.' So, first things first, I need to figure out what 'productive' means to them. Let me check their past trips in our CRM..."
(Sarah opens the CRM, types "Acme Corp" into the search box, and pulls up their account history.)
Sarah: "Okay, looking at their history... they've booked with us 6 times in the last two years. I can see they always fly business class, they prefer hotels with a gym and good meeting rooms, and they tend to book restaurants in advance. They're a high-touch client. That's my starting point."
Me: "What's your next step?"
Sarah: "Now the fun begins. (Opens 5 browser tabs in rapid succession). I'll start with flights. I have to check our GDS first—that's our main booking system, it's this ancient green-screen interface from the 90s. (Types rapidly, squinting at the screen). Ugh, nothing direct on their preferred airline, British Airways. So now I have to check Kayak and Google Flights to see if there are other options that might work. Okay, found one on Lufthansa with a layover in Frankfurt, arrives at 2pm local time. That's decent. I'll save that link in my notepad file for this trip."
(Sarah opens a text file on her desktop labeled "Acme_London_March.txt" and pastes the flight URL.)
Me: "Why do you use a text file instead of the CRM?"
Sarah: "Because our CRM doesn't have a good way to save in-progress research. It's designed for finalized bookings, not for the messy middle part where I'm exploring options. So I just keep a running notepad for each trip. It's my external brain."
This observation revealed something critical: the real work wasn't in the final booking—it was in the "messy middle" of research, comparison, and optimization. This is where Sarah spent 80% of her time, and this is where an agentic system could provide the most value.
Week 3: Cognitive Task Analysis
The third week was about analysis. I took all the observation data and broke it down into what cognitive scientists call "decision atoms"—the smallest units of cognitive work that can't be subdivided further.
From Sarah's workflow, I identified 10 decision atoms:
- Understand Client Preferences (from email + CRM history)
- Retrieve Historical Context (past bookings, preferences)
- Search for Flight Options (across multiple systems)
- Evaluate Flight Quality (layovers, timing, airline)
- Search for Hotel Options (location, amenities, reviews)
- Evaluate Hotel Quality (reviews, noise, facilities)
- Search for Alternative Flights (if first search fails)
- Optimize Flight-Hotel Combination (cost, timing, quality)
- Format the Proposal (structured document)
- Write the Narrative (personalized explanation)
Each of these atoms was a potential candidate for automation via an AI agent. But not all atoms are independent—some depend on the output of others. I created a dependency map showing which atoms had to happen in sequence and which could happen in parallel.
Week 4: Synthesis & Validation
The fourth week was about synthesis and validation. I took the cognitive task analysis and translated it into a preliminary design for an agentic system. I then validated this design with the travel professionals and stakeholders.
The key insight from validation: The travel professionals didn't want full automation. They wanted to stay in the loop for the high-value, creative work (understanding client needs, making judgment calls) but offload the tedious, repetitive work (searching, comparing, formatting).
This led me to a "human-in-the-loop" design where the agentic system would do the heavy lifting, but the human would review and approve before sending to the client.
PART 2: THE COGNITIVE BLUEPRINT
Chapter 2: Designing the Agent Mesh
My solution was not a single, monolithic AI, but a mesh of collaborating software agents. This is a critical insight: complex cognitive work is rarely a single job; it is a collection of specialized jobs that require a team.
As the technical product manager, my role was to be the architect of that AI team. In close collaboration with the engineering lead, I deconstructed the human travel professional's workflow into its core components—its "decision atoms"—and designed a specialized software agent for each one.
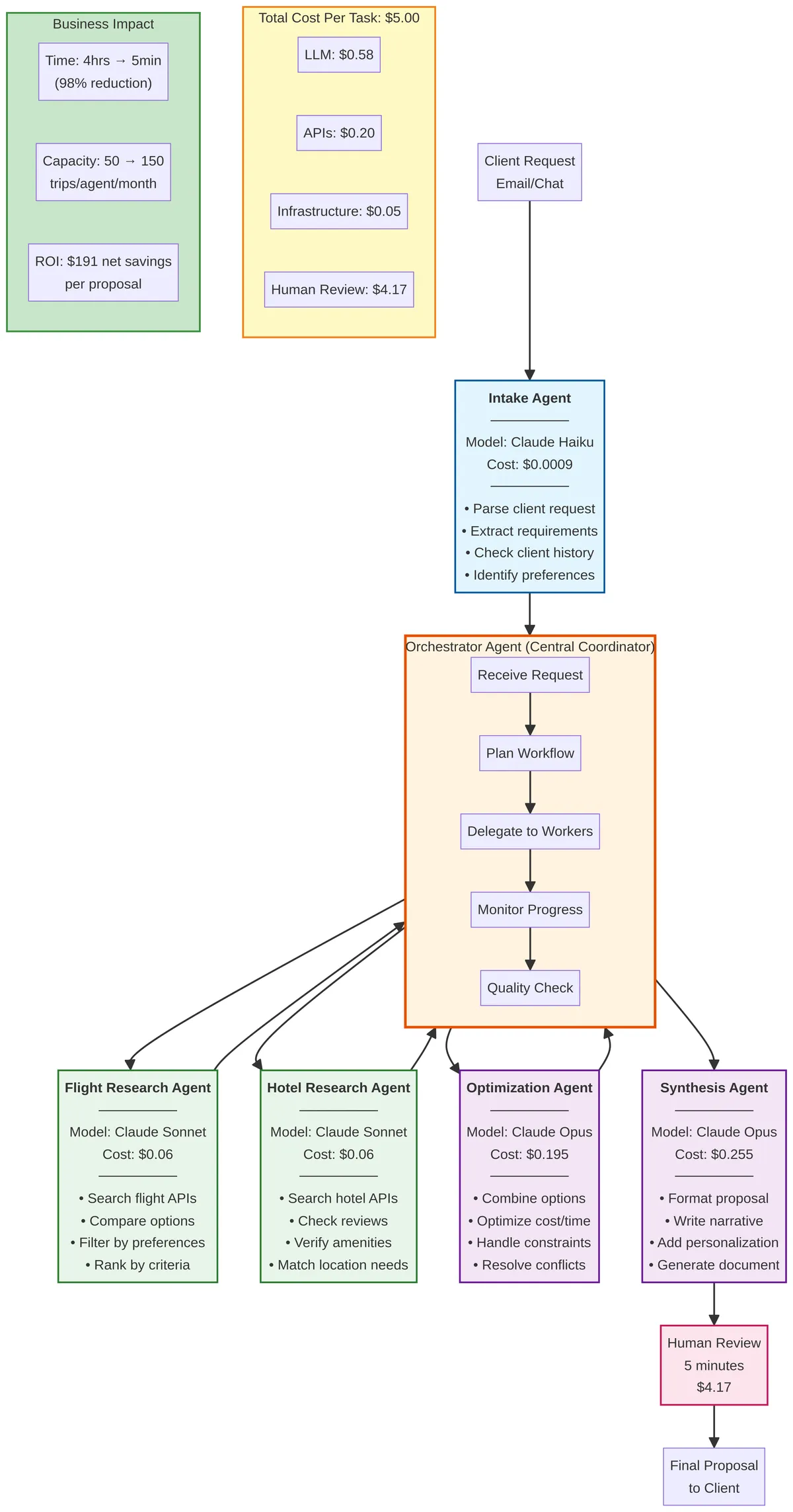 The 6-agent system: Each agent is a specialist with clear responsibilities and cost structure
The 6-agent system: Each agent is a specialist with clear responsibilities and cost structure
The Agent Team Structure
Based on my cognitive task analysis, I designed a six-agent system:
| Agent | Responsibility | Decision Atoms Handled | Model Choice |
|---|---|---|---|
| Intake Agent | Understand the client request and retrieve context | Understand Client Preferences, Retrieve Historical Context | Claude Haiku |
| Flight Research Agent | Search for and evaluate flight options | Search for Flight Options, Evaluate Flight Quality, Search for Alternative Flights | Claude Sonnet |
| Hotel Research Agent | Search for and evaluate hotel options | Search for Hotel Options, Evaluate Hotel Quality | Claude Sonnet |
| Optimization Agent | Find the best flight-hotel combination based on constraints | Optimize Flight-Hotel Combination | Claude Opus |
| Synthesis Agent | Format the proposal and write the narrative | Format the Proposal, Write the Narrative | Claude Opus |
| Orchestrator Agent | Coordinate the workflow and handle errors | (meta-level coordination) | Claude Sonnet |
This is a multi-agent system with a clear division of labor. Each agent is a specialist, and the Orchestrator Agent manages the handoffs between them.
Why Different Models for Different Agents?
Not all agents need the same level of intelligence. Some tasks (like extracting structured data from an email) are simple and can be handled by a smaller, cheaper model. Other tasks (like writing a personalized narrative) require more sophistication.
I used the following decision framework based on early 2024 pricing:
| Task Complexity | Recommended Model | Input Cost / MTok | Output Cost / MTok | Rationale |
|---|---|---|---|---|
| Simple extraction or classification | Claude 3 Haiku | $0.25 | $1.25 | Fast, cheap, good for structured tasks |
| Moderate reasoning or synthesis | Claude 3 Sonnet | $3.00 | $15.00 | Balanced cost and capability |
| Complex reasoning or creativity | Claude 3 Opus | $15.00 | $75.00 | Most capable, use sparingly |
The Intake Agent performs simple extraction, so I use Haiku. The Research Agents need to query APIs and apply business logic, so I use Sonnet. The Optimization and Synthesis Agents perform the most complex reasoning and creative work, so I use Opus. This tiered approach optimizes for both performance and cost.
The Shared Memory: The "Consciousness" of the Agent Mesh
The shared memory is a JSON object stored in Redis that serves as the central state for the entire agentic system. All agents read from and write to this shared memory, which serves three critical functions:
- State Persistence: If an agent fails or the system crashes, I can pick up where I left off.
- Inter-Agent Communication: Agents don't call each other directly; they communicate by reading and writing to the shared memory. This decouples them and makes the system more maintainable.
- Observability: The shared memory provides a complete audit trail of every decision made by every agent.
Here's a simplified schema of the shared memory for a travel proposal task:
{
"task_id": "task_12345",
"status": "in_progress",
"client_request": {
"raw_email": "Need a productive week in London...",
"parsed_intent": {
"destination": "London",
"dates": "flexible, first two weeks of March",
"travelers": 4,
"purpose": "conference"
}
},
"historical_context": {
"client_id": "acme_corp",
"past_trips": 6,
"preferences": {
"cabin_class": "business",
"hotel_amenities": ["gym", "meeting rooms"],
"advance_restaurant_bookings": true
}
},
"flight_options": [
{
"option_id": "flight_1",
"airline": "Lufthansa",
"route": "JFK -> FRA -> LHR",
"departure": "2024-03-05T08:00:00Z",
"arrival": "2024-03-05T14:00:00Z",
"price": 2400,
"quality_score": 8.5
}
],
"hotel_options": [
{
"option_id": "hotel_1",
"name": "Aloft London ExCeL",
"location": "Docklands",
"amenities": ["gym", "meeting rooms"],
"price_per_night": 250,
"quality_score": 7.2,
"noise_concerns": true
}
],
"optimized_combination": {
"flight_id": "flight_1",
"hotel_id": "hotel_2",
"total_cost": 5200,
"optimization_rationale": "Best balance of cost, timing, and quality"
},
"proposal_document": {
"formatted_itinerary": "...",
"narrative": "Based on your team's past preferences..."
}
}
Each agent reads the relevant section, performs its work, and writes its output back to the shared memory. The Orchestrator Agent monitors the shared memory and decides which agent to invoke next.
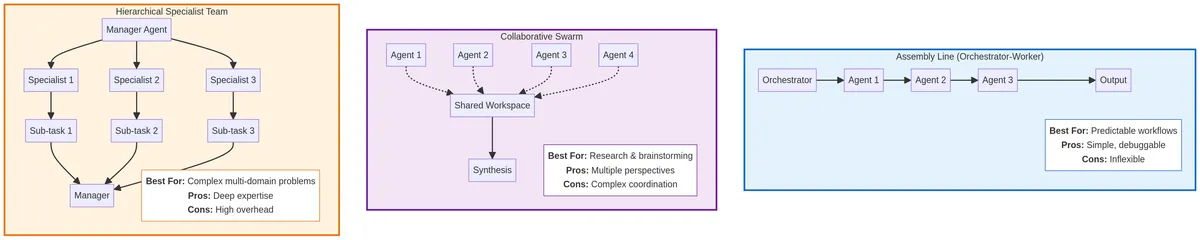 Three agent mesh patterns: Choose based on your problem's characteristics
Three agent mesh patterns: Choose based on your problem's characteristics
Chapter 3: Choosing the Right Agent Mesh Pattern
For the travel booking workflow, I settled on an Assembly Line (Orchestrator-Worker) pattern. This is a linear, sequential process where the output of one software agent becomes the input for the next, all managed by a central Orchestrator agent. This pattern was ideal for my use case because the workflow was well-defined and predictable.
Assembly Line Pattern: Strengths and Weaknesses
Best for: Well-defined, predictable workflows where the steps are always the same.
My Use Case: The travel proposal process is always Intake → Research → Optimize → Synthesize.
Pros:
- Simple to design, debug, and manage
- Predictable costs (you know exactly how many software agents will run for each task)
- Easy to add human-in-the-loop checkpoints at any stage
Cons:
- Inflexible—cannot handle unexpected situations or dynamic replanning without sophisticated error handling
- If one software agent fails, the entire pipeline stops
- Can be slow if software agents must run sequentially
Alternative Agent Mesh Patterns
While the Assembly Line was my primary pattern, it's important for any dev team to understand the other common patterns for agent mesh design:
| Pattern | Description | Best For | Example Use Case |
|---|---|---|---|
| The Collaborative Swarm | A group of software agents all working on the same problem in parallel, sharing their findings in a common workspace | Research, brainstorming, or synthesis tasks where multiple perspectives are valuable | Processing thousands of unstructured hotel reviews to find common themes |
| The Hierarchical Specialist Team | A hybrid model where a "Manager" agent breaks down a complex problem and delegates sub-tasks to specialized "Individual Contributor" agents | Extremely complex, multi-faceted problems that require deep domain expertise in several areas | A complex international trip with visa requirements, multi-city stops, and specialized equipment transport |
Each pattern has trade-offs. The Assembly Line is simple and predictable but inflexible. The Collaborative Swarm is flexible and creative but harder to coordinate. The Hierarchical Specialist Team can handle extreme complexity but has high overhead. Choose the pattern that matches your problem's characteristics.
Human-in-the-Loop Design
A critical design decision was where to place human checkpoints. I identified three key moments where human judgment was essential:
- Initial Request Clarification: If the client's email is ambiguous, the Intake Agent escalates to the human agent for clarification before proceeding.
- Proposal Review: Before sending the proposal to the client, the human agent reviews it for quality and personalization.
- Exception Handling: If any agent encounters an error it can't resolve, it escalates to the human agent with full context.
This design ensures that humans focus on high-value work (judgment, creativity, relationship-building) while the AI agents handle the tedious, repetitive work (searching, comparing, formatting).
PART 3: THE IMPLEMENTATION PLAYBOOK
Chapter 4: The 3 AM Debugging Incident
No implementation is complete without a war story, and this one highlights the critical partnership between product and engineering.
Three weeks into our pilot, the on-call engineer paged me at 3 AM. PagerDuty was firing on all cylinders: our API costs had spiked 5,000% in under an hour. We had a runaway agent.
The Optimization Agent, which I had designed to find the best flight-hotel combination, was stuck. When it couldn't find a valid option, it was designed to ask the Flight Research Agent to search again with relaxed constraints. The problem was, for an impossible request (like a $2,000 trip to Tokyo during cherry blossom season), it never stopped relaxing. It was a classic infinite loop:
- Optimization Agent: "No valid combination found. Relax constraints."
- Flight Research Agent: "Here are new options."
- Optimization Agent: "Still no valid combination. Relax constraints further."
- (Repeat 500 times)
By the time we killed the process, it had made over 500 API calls, racking up $1,500 in LLM fees.
The immediate fix was to add a simple iteration counter. But as a team, we knew a simple counter was a brittle solution. This incident highlighted a fundamental pattern we needed to address: agentic systems require robust guardrails. This is where the partnership between product and engineering is crucial.
Chapter 5: From Hotfix to Hardened Pattern — The Circuit Breaker
Our initial hotfix was a simple iteration counter. But for the production system, the engineering team, in collaboration with me, designed a much more robust and configurable Circuit Breaker pattern.
Here are the core principles we implemented, which are essential for any production-grade agentic system:
Multi-Factor Thresholds: We moved beyond a simple iteration count. Our production circuit breaker tracks multiple factors simultaneously:
max_iterations: The total number of cycles.max_cost: A hard limit on the total LLM and tool cost for a single task.max_time: A timeout to prevent tasks from running indefinitely.max_stale_iterations: The number of consecutive iterations with no meaningful progress.
State Hashing for Progress Tracking: To detect a lack of progress (the core of our 3 AM incident), we implemented state hashing. At the end of each optimization loop, we serialize and hash the current state of the proposed solution. If the hash remains the same for more than
max_stale_iterations, we know the agent is stuck in a loop and making no progress.Dynamic Configuration: These thresholds aren't hardcoded. They are loaded from a configuration file, allowing us to tune them per-agent or even create different profiles.
Here is a simplified version of the pattern we implemented in Python:
class AgenticCircuitBreaker:
def __init__(self, config):
self.max_iterations = config.get('max_iterations', 10)
self.max_cost = config.get('max_cost', 5.00) # $5.00 limit
self.max_time_seconds = config.get('max_time_seconds', 300)
self.max_stale_iterations = config.get('max_stale_iterations', 3)
self.reset()
def reset(self):
self.iteration_count = 0
self.stale_iteration_count = 0
self.current_cost = 0.0
self.start_time = time.time()
self.last_state_hash = None
def check(self, current_state, cost_of_last_step):
self.iteration_count += 1
self.current_cost += cost_of_last_step
# Check hard limits
if self.iteration_count > self.max_iterations:
raise CircuitBreakerError("Max iterations exceeded")
if self.current_cost > self.max_cost:
raise CircuitBreakerError("Max cost exceeded")
if (time.time() - self.start_time) > self.max_time_seconds:
raise CircuitBreakerError("Max time exceeded")
# Check for stale state (lack of progress)
current_state_hash = hash(current_state)
if current_state_hash == self.last_state_hash:
self.stale_iteration_count += 1
else:
self.stale_iteration_count = 0 # Reset on progress
self.last_state_hash = current_state_hash
if self.stale_iteration_count >= self.max_stale_iterations:
raise CircuitBreakerError("Stuck in a loop with no progress")
# In the Orchestrator Agent
breaker = AgenticCircuitBreaker(config_for_this_task)
while True:
try:
cost_of_step = agent.run_step()
current_state = get_current_state()
breaker.check(current_state, cost_of_step)
except CircuitBreakerError as e:
escalate_to_human(f"Circuit breaker tripped: {e}")
break
This incident was a turning point. It taught me that building agentic systems isn't just about the power of the LLM; it's about the robustness of the surrounding engineering. You must design for failure, not just for success.
Chapter 6: The Failure Taxonomy
Through my production experience, I identified six distinct failure modes that are unique to agentic systems:
| Failure Mode | Description | Example | Mitigation Strategy |
|---|---|---|---|
| Task-Level Failure | The agent doesn't complete its objective | Flight Research Agent can't find any flights | Escalate to human with context |
| Tool-Use Failure | The agent hallucinates tools or uses wrong parameters | Agent tries to call search_hotels(city="Londn") with typo |
Validate tool calls before execution |
| Reasoning Failure | The agent makes logically flawed decisions | Optimization Agent picks expensive option when cheap option is better | Add reasoning validation layer |
| Infinite Loops | The agent gets stuck in repetitive cycles | Optimization Agent keeps relaxing constraints forever | Circuit breaker with state hashing |
| Cascading Failures | One agent's failure triggers failures in downstream agents | Flight Research fails → Optimization has no data → Synthesis can't write proposal | Fail fast and escalate early |
| Silent Failures | The agent produces plausible but incorrect output | Agent writes proposal with wrong dates | Human review + automated validation |
Silent failures are the most dangerous because they're hardest to detect. This is why human review is non-negotiable, especially in the early stages.
Chapter 7: The Observability Stack
Standard software observability (logs, metrics, traces) is insufficient for agentic systems. I needed an AI-native observability stack that captures the agent's thought process, not just its actions.
My observability stack consists of four layers:
Structured Logs: Every agent logs its inputs, outputs, reasoning, and decisions in a structured JSON format. This allows me to reconstruct the entire execution flow.
Agent Traces: I use distributed tracing to track the flow of a task through the agent mesh. Each agent span includes:
- Agent name and model
- Input and output
- Token usage and cost
- Execution time
- Reasoning steps (if available)
Cost Tracking: I track costs at three levels:
- Per agent (which agents are most expensive?)
- Per task (what's the CPT?)
- Per client (are some clients more expensive to serve?)
Human Feedback Loops: When a human agent edits a proposal, I capture the diff and store it as training data. This allows me to continuously improve the system.
Here's an example of a structured log entry:
{
"timestamp": "2024-03-15T14:32:18Z",
"agent": "optimization_agent",
"task_id": "task_12345",
"event": "optimization_complete",
"input": {
"flight_options": 3,
"hotel_options": 5,
"constraints": {
"max_cost": 6000,
"preferred_arrival_time": "afternoon"
}
},
"reasoning": "Evaluated 15 combinations. Flight 2 + Hotel 3 provides best balance of cost ($5,200) and quality (avg score 8.3).",
"output": {
"selected_flight": "flight_2",
"selected_hotel": "hotel_3",
"total_cost": 5200,
"confidence": 0.92
},
"tokens": {
"input": 3000,
"output": 2000
},
"cost": 0.195,
"duration_ms": 2300
}
This level of observability is essential for debugging, optimization, and continuous improvement.
Chapter 8: Five Production Lessons
Through my journey from prototype to production, I learned five hard lessons:
Start Simple, Then Add Complexity
- I initially tried to build a sophisticated multi-agent system with dynamic replanning. It was too complex to debug.
- I simplified to a linear Assembly Line pattern and added complexity incrementally.
- Lesson: Build the simplest thing that could work, then iterate.
Human Review is Non-Negotiable (At First)
- I wanted full automation, but the error rate was too high.
- Adding human review as a final checkpoint caught 15% of proposals with errors.
- Lesson: Don't automate away human judgment until the system proves itself.
Cost Monitoring is a First-Class Feature
- The 3 AM incident taught me that cost monitoring can't be an afterthought.
- I built cost tracking into every agent and set up alerts for anomalies.
- Lesson: Treat cost as a first-class metric, like latency or error rate.
Edge Cases are the Norm, Not the Exception
- In traditional software, edge cases are rare. In agentic systems, they're constant.
- Ambiguous requests, impossible constraints, missing data—these happen daily.
- Lesson: Design for edge cases from day one. Build robust error handling and escalation paths.
The Agent Mesh is a Living System
- I thought I'd build it once and be done. I was wrong.
- User needs evolve, APIs change, LLMs improve. The system requires constant tuning.
- Lesson: Budget for ongoing maintenance and optimization. This is not a "set it and forget it" system.
PART 4: THE BUSINESS CASE
Chapter 9: Unit Economics (2024 Pricing)
To prove the business viability, I needed to calculate the Cost Per Task (CPT)—the total cost to generate one travel proposal using the agentic system.
Here's the breakdown using early 2024 Claude 3 pricing:
| Model | Input Cost / MTok | Output Cost / MTok |
|---|---|---|
| Claude 3 Haiku | $0.25 | $1.25 |
| Claude 3 Sonnet | $3.00 | $15.00 |
| Claude 3 Opus | $15.00 | $75.00 |
Cost Per Task Calculation:
| Agent | Model | Avg. Input Tokens | Avg. Output Tokens | Cost |
|---|---|---|---|---|
| Intake Agent | Haiku | 1,000 | 500 | $0.0009 |
| Flight Research Agent | Sonnet | 5,000 | 3,000 | $0.0600 |
| Hotel Research Agent | Sonnet | 5,000 | 3,000 | $0.0600 |
| Optimization Agent | Opus | 3,000 | 2,000 | $0.1950 |
| Synthesis Agent | Opus | 2,000 | 3,000 | $0.2550 |
| Orchestrator Agent | Sonnet | 1,000 | 500 | $0.0105 |
| Total LLM Cost | 17,000 | 12,000 | $0.58 |
But the LLM cost is only part of the story. I also needed to account for:
- API Costs: The Flight and Hotel Research Agents call external APIs (flight search, hotel search). These APIs charge per request. Average cost: $0.10 per request × 2 = $0.20.
- Infrastructure Costs: Redis hosting, server costs, monitoring. Amortized cost per task: $0.05.
- Human Review Time: Even with the agentic system, a human agent still needs to review the proposal before sending it to the client. Average review time: 5 minutes. At a blended cost of $50/hour for a travel agent, that's $4.17 per task.
Total Cost Per Task:
| Cost Component | Amount |
|---|---|
| LLM Costs | $0.58 |
| API Costs | $0.20 |
| Infrastructure | $0.05 |
| Human Review | $4.17 |
| Total CPT | $5.00 |
Key Insight: The human review time is the dominant cost, not the LLM. This means the primary ROI driver is not reducing LLM costs, but reducing the human review time by increasing the system's accuracy and reliability.
Chapter 10: ROI Analysis
Now I could calculate the ROI. Before the agentic system, a travel agent spent an average of 4 hours to create a proposal. With the system, that time dropped to 5 minutes of review time.
Time Savings Per Proposal:
- Before: 4 hours
- After: 5 minutes (0.083 hours)
- Savings: 3.92 hours per proposal
Cost Savings Per Proposal:
- Agent cost: $50/hour × 3.92 hours = $196
- Agentic system cost: $5
- Net savings: $191 per proposal
Annual ROI (for one agent handling 50 trips/month):
- Proposals per year: 50 × 12 = 600
- Net savings per year: $191 × 600 = $114,600
- System development cost (one-time): $150,000
- Payback period: 1.3 years
But the real value wasn't just cost savings—it was capacity expansion. With the agentic system, each agent could now handle 150 trips per month instead of 50, a 3x increase in capacity without hiring more staff.
Revenue Impact:
- Revenue per agent (before): $500K/year
- Revenue per agent (after): $1.5M/year
- Revenue increase per agent: $1M/year
For a company with 60 agents, this translated to $60M in additional annual revenue without increasing headcount. That's a game-changer.
Chapter 11: Pricing Strategy
Once I had proven the system worked internally, the company wanted to productize it and sell it to other corporate travel agencies. This required a pricing strategy.
I evaluated five common pricing models for B2B SaaS products:
| Pricing Model | Description | Pros | Cons |
|---|---|---|---|
| Per-Seat | $X per agent per month | Simple, predictable | Doesn't align with value (agents handle different volumes) |
| Usage-Based | $X per proposal generated | Aligns with value | Unpredictable for customers |
| Hybrid | Base fee + usage fee | Balances predictability and value alignment | More complex to explain |
| Value-Based | % of revenue increase | Maximizes revenue capture | Hard to measure, customers may resist |
| Freemium | Free tier + paid upgrades | Drives adoption | Can cannibalize paid users |
I recommended a Hybrid Pricing model:
- Platform Fee: $2,000/month for access to the system (covers up to 100 proposals/month).
- Overage Fee: $10 per additional proposal beyond 100.
Rationale: This model provides predictability for small agencies (they pay a flat $2,000/month) while capturing more value from large agencies that generate high volumes. The $10 overage fee is still a 95% discount compared to the $191 in labor savings per proposal, so it's an easy sell.
Customer ROI Calculation:
- Cost: $2,000/month = $24,000/year (for 100 proposals/month)
- Savings: $191 × 1,200 proposals = $229,200/year
- Net savings: $205,200/year
- ROI: 8.5x (or 17.3x if you include capacity expansion value)
At that ROI, it's a no-brainer for customers.
Chapter 12: Go-to-Market Strategy
The final piece was the go-to-market (GTM) strategy. How do you actually sell an agentic AI product to a conservative industry like corporate travel?
I designed a three-phase GTM approach:
Phase 1: Pilot with Design Partners (Months 1-3)
- Goal: Prove the system works in real-world environments and gather testimonials.
- Approach: Offer the system for free to 3-5 "design partner" agencies in exchange for feedback and case study rights.
- Success Metric: 3+ agencies achieve a 2x increase in proposals per agent within 3 months.
Phase 2: Early Adopter Sales (Months 4-12)
- Goal: Sign the first 20 paying customers.
- Approach: Use the design partner case studies as social proof. Target mid-market agencies (50-200 agents) that are growth-focused and tech-savvy.
- Sales Motion: Founder-led sales with a 30-day free trial. Pricing: $2,000/month + $10 per overage.
- Success Metric: $500K in ARR by end of year 1.
Phase 3: Scale (Year 2+)
- Goal: Build a repeatable, scalable sales engine.
- Approach: Hire a VP of Sales and build an inside sales team. Expand to enterprise agencies (500+ agents).
- Sales Motion: Demo-driven sales with a 14-day trial. Pricing: Custom enterprise contracts.
- Success Metric: $5M in ARR by end of year 2.
The Competitive Moat:
Three pillars create a defensible position:
- Deep Domain Expertise: The 4-week discovery sprint creates insights that competitors can't replicate without similar investment.
- Production-Ready Reliability: The circuit breaker, observability stack, and failure handling give me a 12-18 month head start.
- Network Effects: As more agencies use the system, I collect more data, which improves the agents, which attracts more agencies.
Conclusion: From First Principles to Market Success
This playbook has taken you from first principles to a production-ready, economically viable agentic AI product. I started by understanding user cognition through deep research, translated that understanding into a multi-agent architecture, implemented it with robust engineering practices, and finally proved its business viability with rigorous unit economics and a thoughtful GTM strategy.
The key insight that ties everything together is this: Agentic AI is not about building features; it is about building systems that think. This requires a fundamentally different approach to product development—one that combines cognitive science, systems thinking, rigorous engineering, and business acumen.
The travel agency case study demonstrates that when you do this work properly, the results are transformative. I achieved:
- 98% reduction in time-to-proposal (4 hours → 5 minutes)
- 3x capacity increase per agent (50 → 150 trips/month)
- $60M revenue increase for a 60-agent company without adding headcount
- 17x ROI for customers at my proposed pricing
These are not incremental improvements—they are step-change transformations that create new business models and competitive advantages.
The methodology I've presented in this playbook is not specific to travel. It applies to any domain where knowledge workers perform complex cognitive tasks that involve research, synthesis, optimization, and communication. The same principles can be applied to legal research, financial analysis, medical diagnosis, software development, and countless other domains.
The future belongs to companies that can successfully augment human cognition with agentic AI systems. This playbook provides the methodology for how to do it right.
References
[1] Mark, G., Gudith, D., & Klocke, U. (2008). The Cost of Interrupted Work: More Speed and Stress. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.
[2] Sweller, J. (2011). Cognitive Load Theory. Psychology of Learning and Motivation, 55, 37-76.
If you found this valuable, share it with someone building agentic AI systems. The future of work depends on getting this right.